The Practical Guide to Executing an Orchestration with Sofie
Multi-agent orchestrations are changing how biopharma teams produce documentation. This guide covers how they work, why general-purpose AI falls short in regulated environments, and what it takes to use them well.

Suraj Palaparty
Biopharma documentation is built under conditions that make consistency difficult. Process scientists, quality engineers, and regulatory affairs professionals work across dozens of source materials under compressed timelines, and not every document gets assembled with the same level of depth and rigor. That is not a failure of effort. It reflects what happens when scope, time pressure, and cognitive load converge within a single working session. Even in well-run operations, the combination of volume and urgency creates conditions where a critical detail is missed, a reference goes unverified, or a decision is framed without the full context the data supports.
That gap is closing. Multi-agent orchestrations, AI workflows purpose-built for biopharma operations, can now execute the documentation-heavy work that has traditionally consumed your team's most productive hours. Multiple specialized agents work through each stage, reading your source documents, extracting the information that matters, drafting structured outputs, and flagging areas of uncertainty for human review. The result is high-quality first drafts grounded in your actual data, produced in a fraction of the time.
The teams getting real results from orchestrations are not just clicking run. These teams are deliberate and comprehensive in how they configure each run. This guide walks through what that looks like: what to prepare, how execution works, and how to review what comes out.
What is an Orchestration?
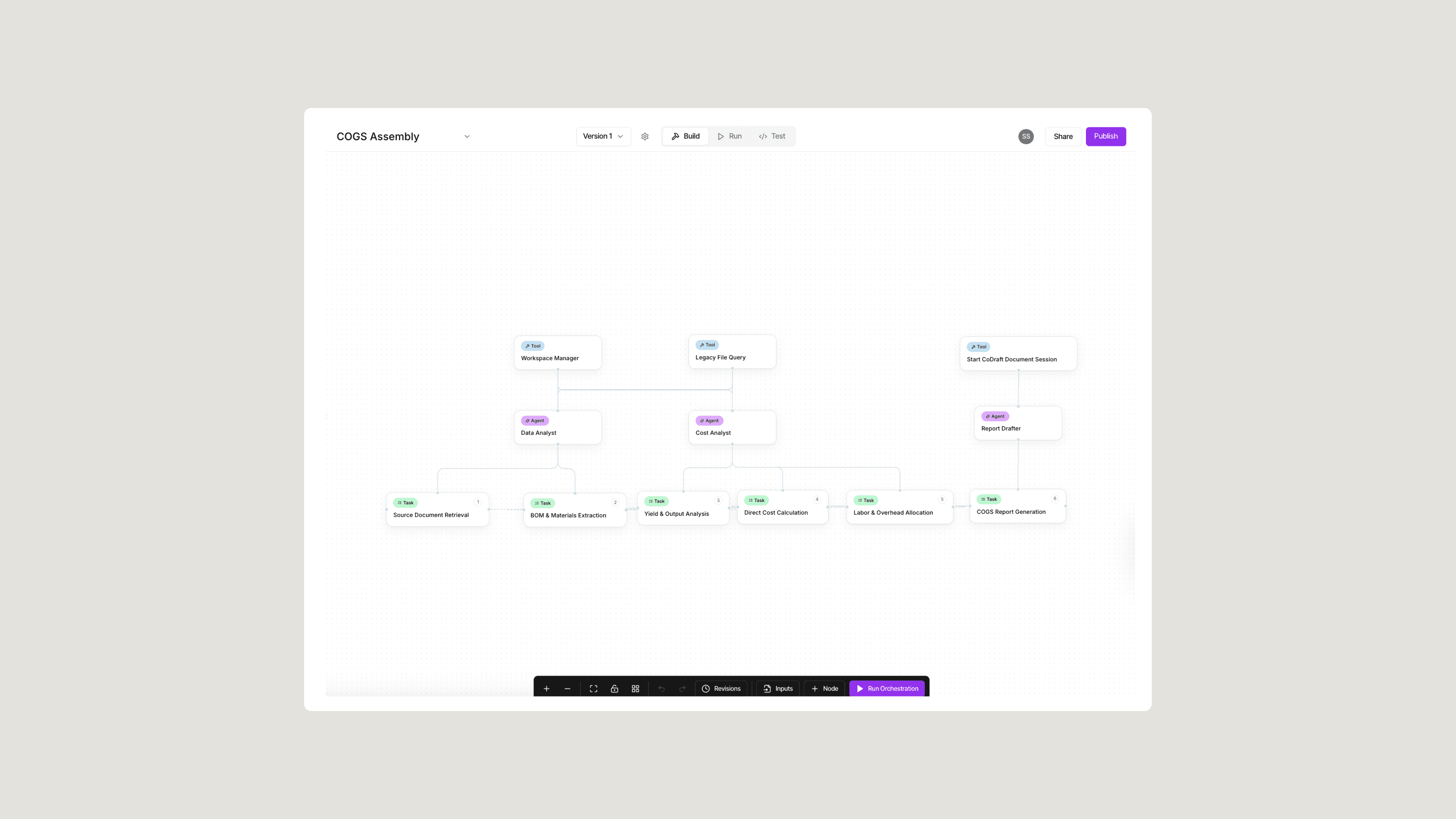
An orchestration is a multi-step, multi-agent workflow that executes a defined objective autonomously with human oversight built in at the decision points that matter. It is not a single AI model answering a question. It is a structured sequence of specialized agents, each completing a defined stage of the workflow and passing its output as full context to the next. One agent retrieves and organizes your source documents. Another extracts the data points the task requires. A third drafts the structured output. A fourth reviews what was produced against your reference materials and flags discrepancies for human attention. Each step runs with a defined role, so the output is consistent whether it is the first run or the hundredth, across every product, site, and team.
In practice, that could mean an orchestration that reads a batch record, identifies deviations, pulls relevant SOPs, generates a root cause analysis, and drafts a CAPA the same way your quality team would — step by step, with full traceability. Or an orchestration that monitors a stability study, flags out-of-trend results, and prepares a regulatory-ready summary. Sofie launches today with 30+ pre-built orchestrations designed for the workflows biopharma teams run every day, and each one can be cloned, customized, or rebuilt from scratch to reflect how your organization actually works. From document-heavy compliance workflows to multi-step analytical review processes, orchestrations turn your team's best practices into guided, one-click execution that delivers high-quality output ready for review.
The term covers several distinct capabilities rather than a single function. Document ingestion and classification, data extraction, cross-reference analysis, structured drafting, and uncertainty flagging all operate within a single orchestration. Some teams use them for a specific document type. Others are building them across the full documentation lifecycle. The scope depends on the workflow and how your workspaces are organized, but the underlying principle is the same: agents handle the volume and repetitive analytical work so your team can focus their time on applying their expertise where it matters most.
The Problem Orchestrations Solve
Even with a slew of AI tools available, it helps to be precise about what the traditional documentation process looks like and where it breaks down. The mechanics of biopharma documentation have not changed much in decades. A batch completes, a deviation occurs, a tech transfer milestone is reached, and teams begin working through source materials under compressed timelines. For a single deviation investigation, that means pulling the deviation record, locating relevant SOPs, reviewing historical incidents, synthesizing analytical data, and drafting a structured report that will withstand regulatory scrutiny often within days of the event.
In practice, documentation is structured around prioritization. Teams focus attention on the highest-risk elements while working through the broader document set as efficiently as they can. The challenge is that maintaining depth, consistency, and accuracy across complex workflows under time pressure depends on human judgment being applied consistently over long stretches of analytical work. Even in well-run operations, variability in how individuals approach the same task is an inherent part of the process.
Documentation is one of the most resource-intensive phases of any biopharma operation, and the timelines governing it are rarely flexible. A batch release delay carries direct revenue implications. A deviation investigation that extends past its target window creates compliance exposure. Teams face constant pressure to move faster without sacrificing quality, and relying on institutional knowledge and manual processes make this almost impossible to avoid.
The demand on your team is high and constant. Reviewer fatigue sets in after hours of working through the same processes for every project and variability is inevitable as different team members may interpret the same SOP section differently depending on their experience and how deep they are into the project. A reviewer working through a technology transfer package cannot simultaneously hold the sending site's full deviation history, the regulatory submission's process commitments, and the receiving site's current capabilities in mind. The gaps that form in that blind spot are exactly where quality risks hide.This is the operational reality, not an anomaly.They are the everyday realities of how biopharma documentation gets done, and they are the problems orchestrations have been built to resolve.
What Happens Inside an Orchestration
Orchestrations include a set of distinct capabilities that map to each stage of a defined workflow. Each agent, task, and tool serves a specific purpose within that structure. What follows explains what happens at each stage.
Documents and context in workspaces
Before any workflow begins, the orchestration needs access to the right source material. Agents pull context directly from your workspace at each step of the run, which means the workspace itself is part of the configuration. Keep it scoped to a single product, program, or project, and maintain current, approved documents only. Agents retrieve from what is there, not just from what is relevant.
The right documents depend on the workflow. A batch release run needs batch records, analytical results, and environmental monitoring data. A deviation investigation needs the deviation record, governing SOPs, and any prior related events. A tech transfer needs process descriptions, analytical methods, and site-specific context from both the sending and receiving sites. Reference SOPs and output templates belong in the workspace for the same reason: agents use them to anchor the analysis and shape the structure of the final document. Everything in the workspace is working material.
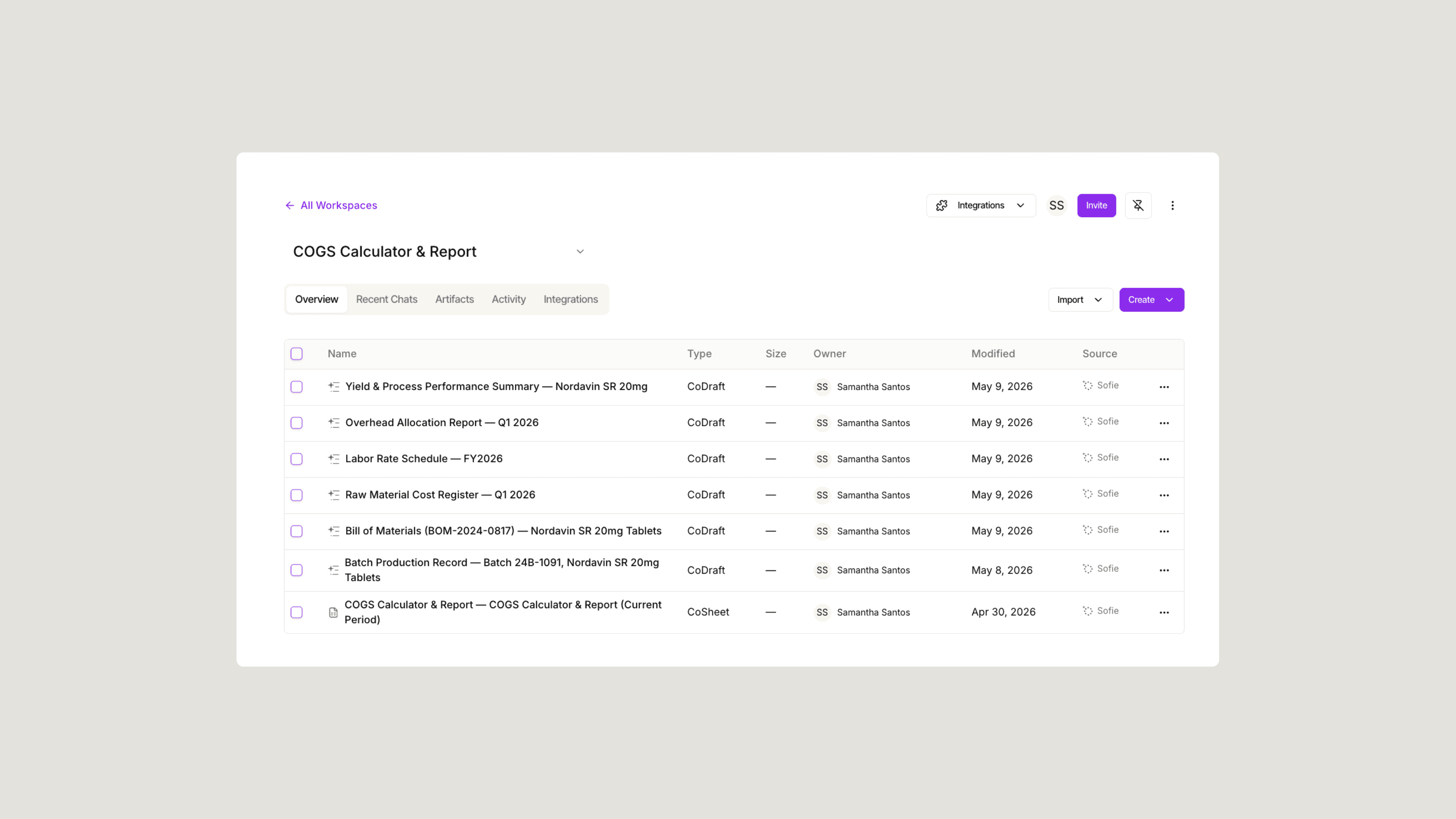
Configuring inputs
Before the first agent runs, Sofie prompts for a set of inputs. These aren't optional; they are the parameters that scope the entire workflow: which documents agents retrieve, how they interpret what they find, and what the output is organized around.
The workspace selector points the run at the right source documents. The product or system name scopes retrieval, which matters most when a workspace spans multiple programs. A lot or batch number is essential for manufacturing and release workflows; without it, agents cannot distinguish batch-specific data from historical records. Document type and scope fields reward specificity: "IQ Protocol for Bioreactor System B" produces meaningfully more targeted output than "IQ Protocol."
The contextual notes field carries more weight than most teams expect. A single sentence of background not captured anywhere in the workspace, such as "this is a first-in-human batch with accelerated release requirements," changes how agents prioritize and frame output across every subsequent step.
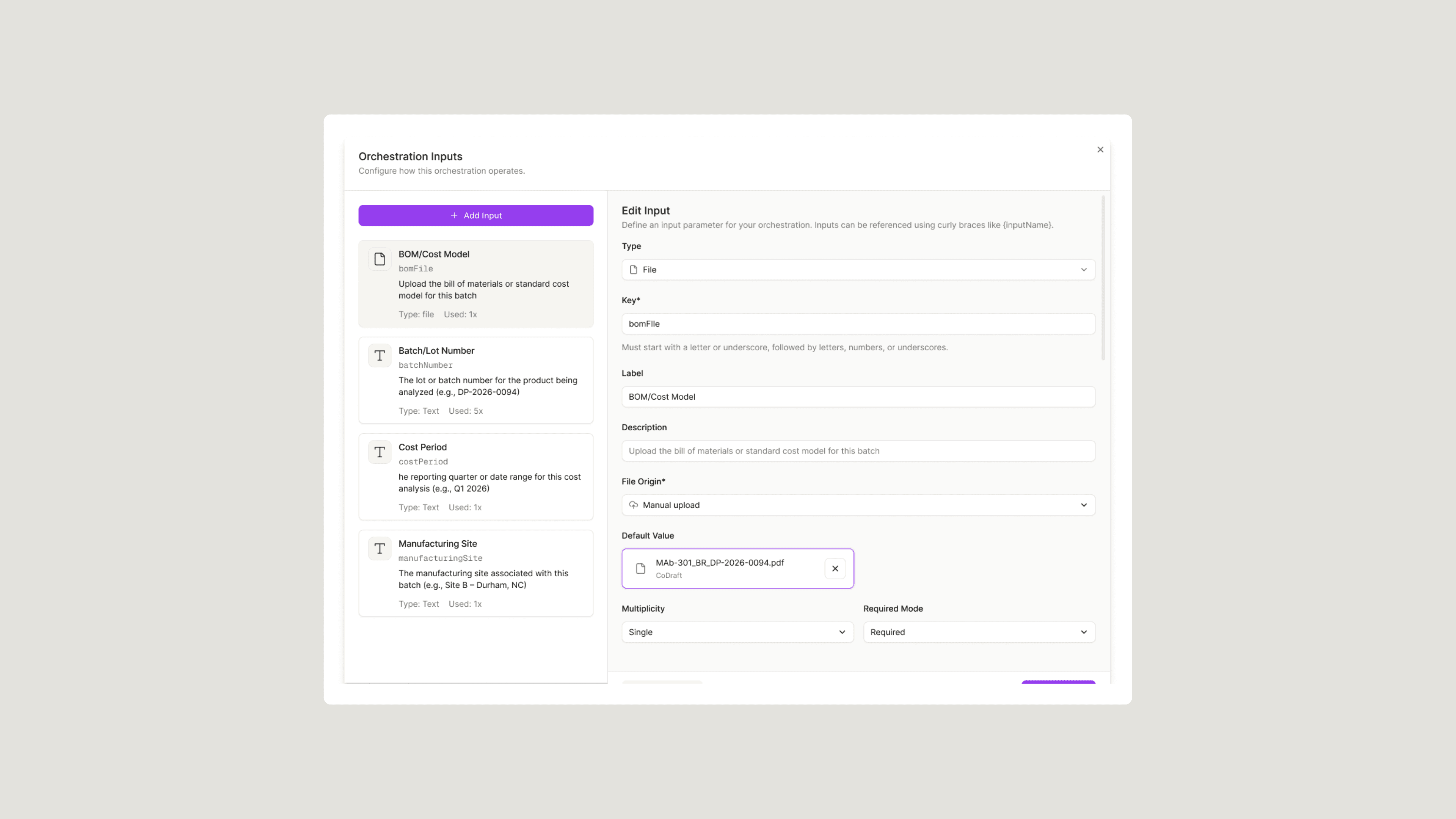
Step-by-step execution of agents
Once a run starts, the orchestration moves through its tasks in a defined order. Each step is handled by a specialized agent that completes its work and passes the full output as context to the next. That continuity is what makes orchestrations different from a series of independent prompts: each agent builds on everything that came before, so the final document reflects the complete scope of the analysis, not just the last step. The process is consistent whether it is the first run or the hundredth, across every product, site, and team.
Orchestrations execute autonomously from start to finish. Intake, document retrieval, and initial context-gathering are the most time-intensive steps, and no visible output surfaces during this phase. Most orchestrations deliver the final document as the last task output, not incrementally throughout. A well-scoped run with a clean workspace typically completes in 8 to 15 minutes. If there's uncertainty about an input value, resolve it before launching. The run will not pause mid-execution to ask.
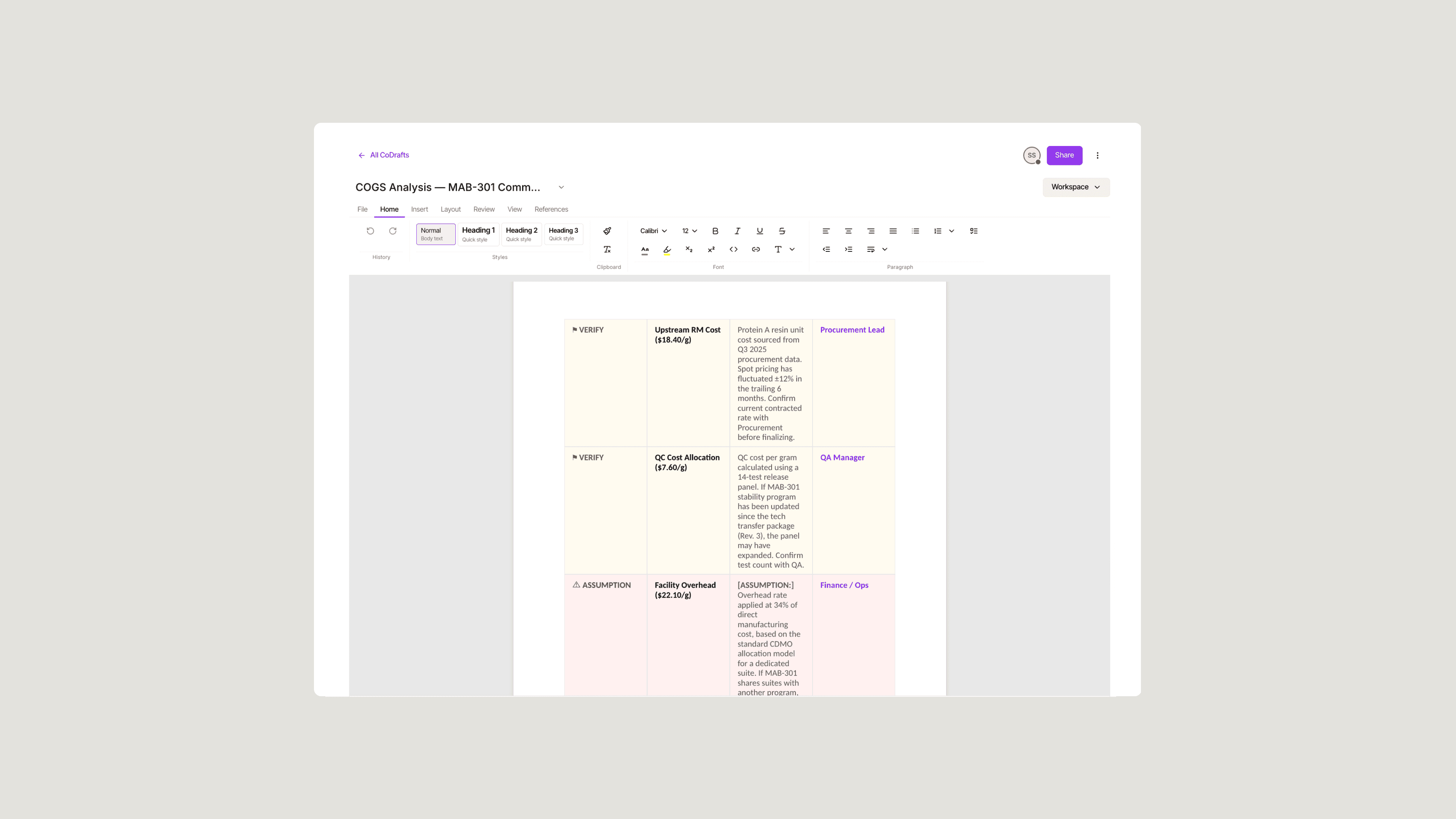
Output review and quality check
When a run completes, you receive a structured document output. Treat it as a comprehensive first draft. That framing determines what kind of review it needs and where it goes next.
Before routing it for substantive technical review, run a focused QC pass, not line by line, but targeted at the elements most likely to carry errors.
Start with identifiers. Verify that lot numbers, product names, and dates match your inputs exactly; transcription errors on these are the most common and most consequential. Check any SOP numbers, method references, or regulatory citations against your actual source documents. Agents cite what they find. Confirm what they found was correct. Abbreviated, generic, or placeholder-like sections signal that the agent did not find sufficient source material. For GMP documents, confirm that the framing and language are consistent with your site's quality standards and the applicable regulatory framework.
Orchestrations surface uncertainty directly in the output using structured flags: [VERIFY: confirm lot number against LIMS] or [ASSUMPTION: batch size based on process description — confirm with manufacturing record]. These are not errors. They mark where an agent inferred rather than confirmed, giving the reviewer a targeted checklist instead of a full document audit.
Where Orchestrations Fit Across Your Operations
Orchestrations are not limited to one phase of the biopharma operations lifecycle. They apply wherever a workflow requires reading, synthesizing, and drafting from source materials.
Here’s just some of the way orchestrations fit into your operations:
Batch release documentation — Orchestrations ingest batch records, analytical results, and reference specifications to draft the structured release package in a fraction of the time. The release decision stays with the qualified individual; the assembly work doesn't.
Deviation investigation — Orchestrations retrieve the deviation record, reference relevant SOPs, and draft the full investigation report including root cause sections and CAPA frameworks. Teams spend less time on compilation and more time on the analysis that shapes quality outcomes.
Technology transfer — Orchestrations work across the full document set, surface discrepancies between sending and receiving site records, and draft structured summaries that give transfer teams a grounded starting point for technical review.
Protocol development — Orchestrations read reference documents and site specifications, then draft IQ, OQ, PQ, and validation protocols aligned to regulatory requirements. Teams get a high-quality first draft ready for focused review — not a blank page.
Why General-Purpose AI Falls Short in Biopharma Operations
Many biopharma operations teams have experimented with general-purpose AI tools. Some are already embedded in the software they use every day; others have earned strong reputations for producing fluent, well-structured outputs. The problem is not that these tools are poorly built. The problem is that they were built for everything, which in biopharma means they were built for nothing specific enough to matter. A model trained on broad data does not know the difference between a critical quality attribute and a key performance indicator. It cannot recognize when a process parameter is missing a regulatory commitment, or when a deviation narrative has drifted from the evidentiary standard a site's quality system requires. Fluent output is not the same as accurate output, and in regulated operations that distinction has consequences.
There are four attributes that separate Sofie from general-purpose tools in a regulated environment.
The first is domain grounding. When models are evaluated against how qualified professionals actually draft deviation reports, review batch records, and write regulatory responses, the outputs reflect the standards those professionals apply. General models may produce outputs that sound plausible but often lack the precision that GxP work demands.
The second is citation traceability. Every claim, finding, or referenced value in a regulated document needs to trace back to a specific source: a specific record, a specific section, a specific data point. If an AI tool cannot show where its answer came from, the output cannot be used as the basis for any documented decision. In biopharma, where conclusions carry quality and compliance consequences regardless of document type, verifiability is not a feature. It is a professional requirement.
The third is data security. The source documents in a workspace, from batch records and analytical data to process descriptions and regulatory submissions, are among the most sensitive assets in an organization. The platform handling that data needs to ensure isolation between customer environments and must not use customer data to train underlying models. Getting this wrong is not a technical failure. It is a compliance exposure.
The fourth is workflow fit. General-purpose tools require teams to adapt their work to the tool, constructing prompts, reformatting outputs, and manually verifying results against site standards before anything is usable. Sofie is designed the other way around. It understands the document types, quality frameworks, and regulatory context that biopharma teams work within, so outputs arrive in a form that biopharma operations teams can actually use without reconstruction.
How Orchestrations Fit Into Your Team
Sofie adds a capability to your team without disrupting how it operates. It fits into existing workflows, adapts to the standards and practices your team has already established, and aligns more closely to how your team works over time. None of this means that any role on your team gets smaller. It means that every team member can spend more time focused on work that requires their expertise. Less time assembling documents from source material and more time on the technical judgment, the quality decisions, and the regulatory strategy that determine outcomes.
Adoption across the biopharma industry is accelerating. Large organizations have already moved from evaluation to implementation, and the gap between teams running AI-assisted workflows and those that are not is widening. For small and mid-sized biopharma teams, the question is no longer whether to adopt AI, It is how to do it. Sofie is the platform that makes this shift accessible to every biopharma team, not just those with enterprise AI budgets and dedicated implementation resources.
If your team is still evaluating whether AI is ready for your biopharma workflows, let’s talk.